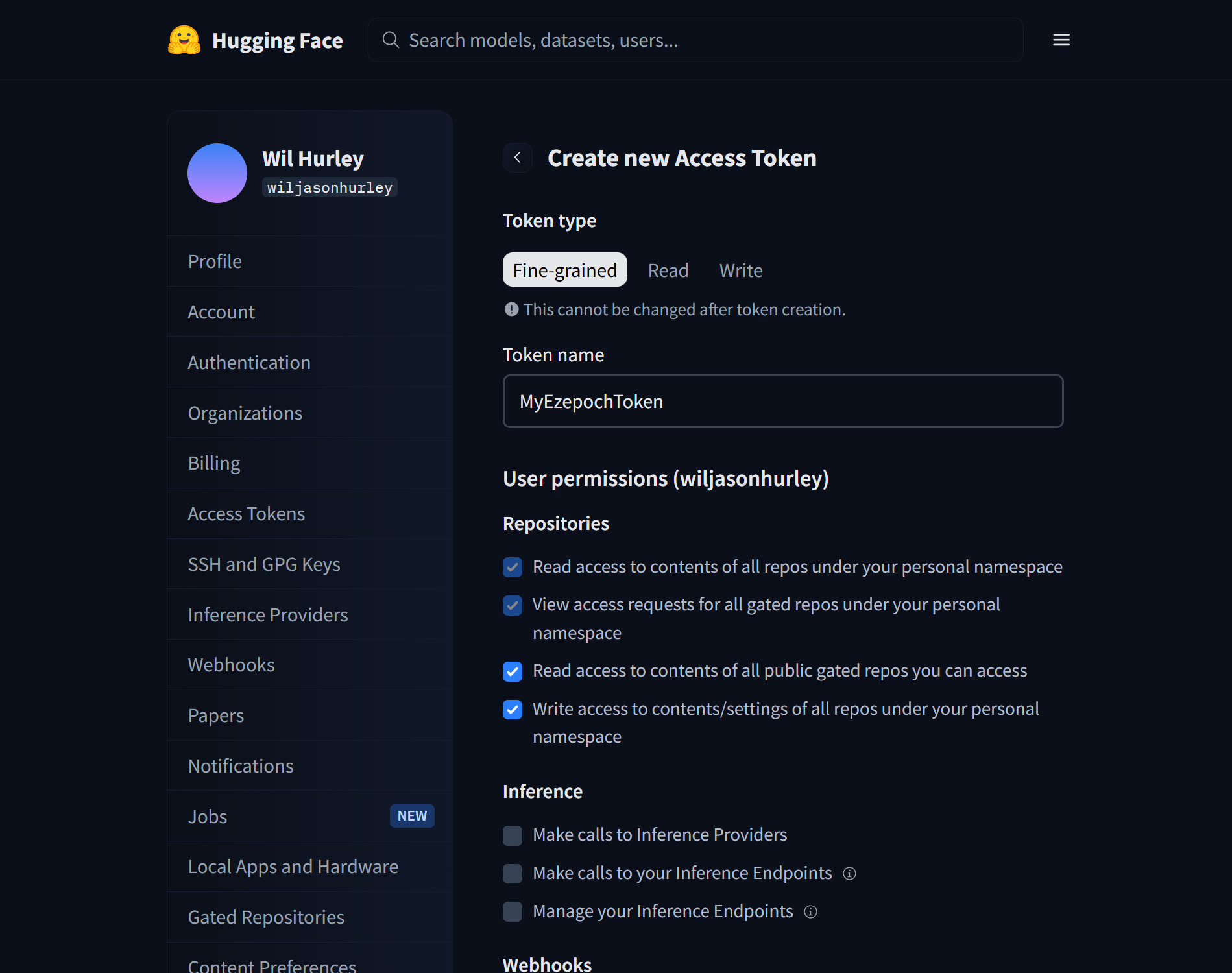
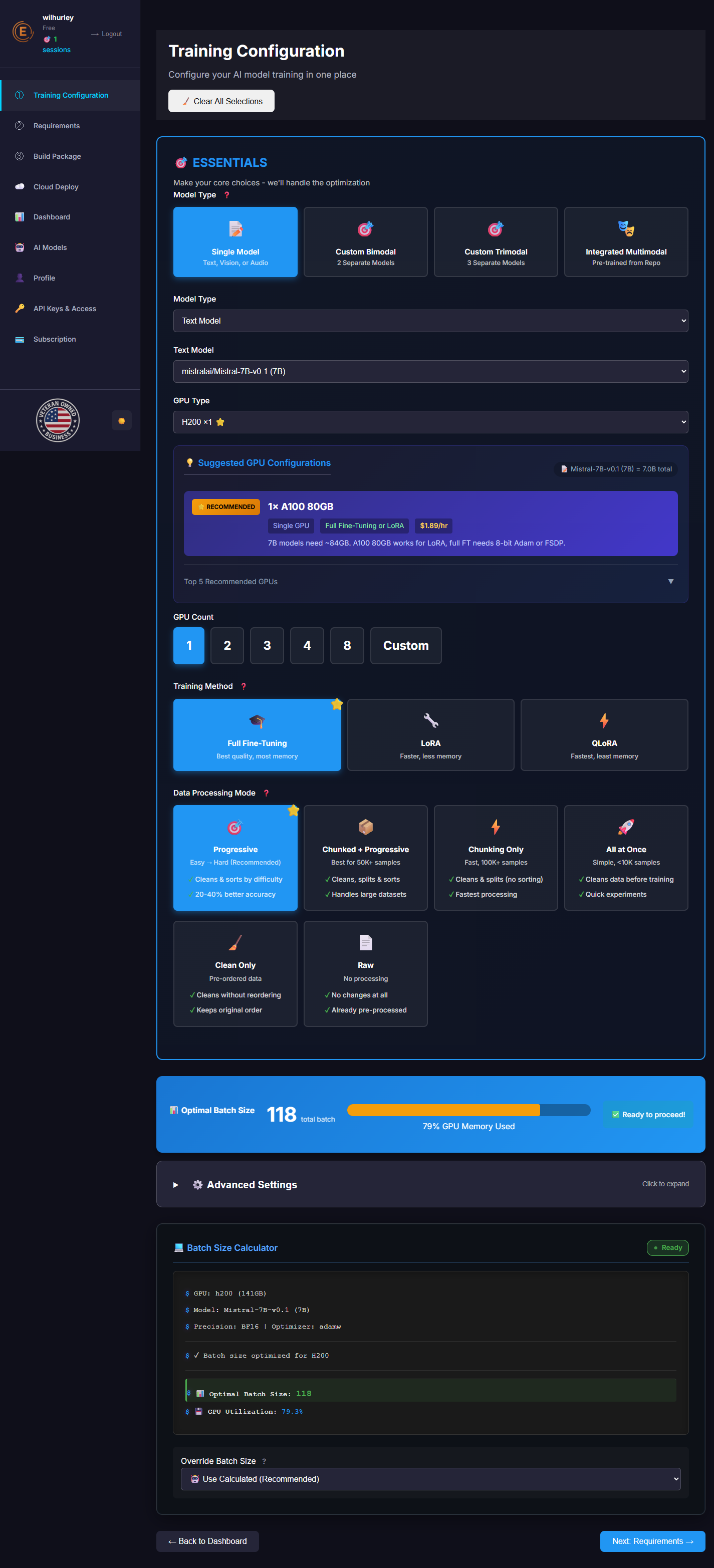
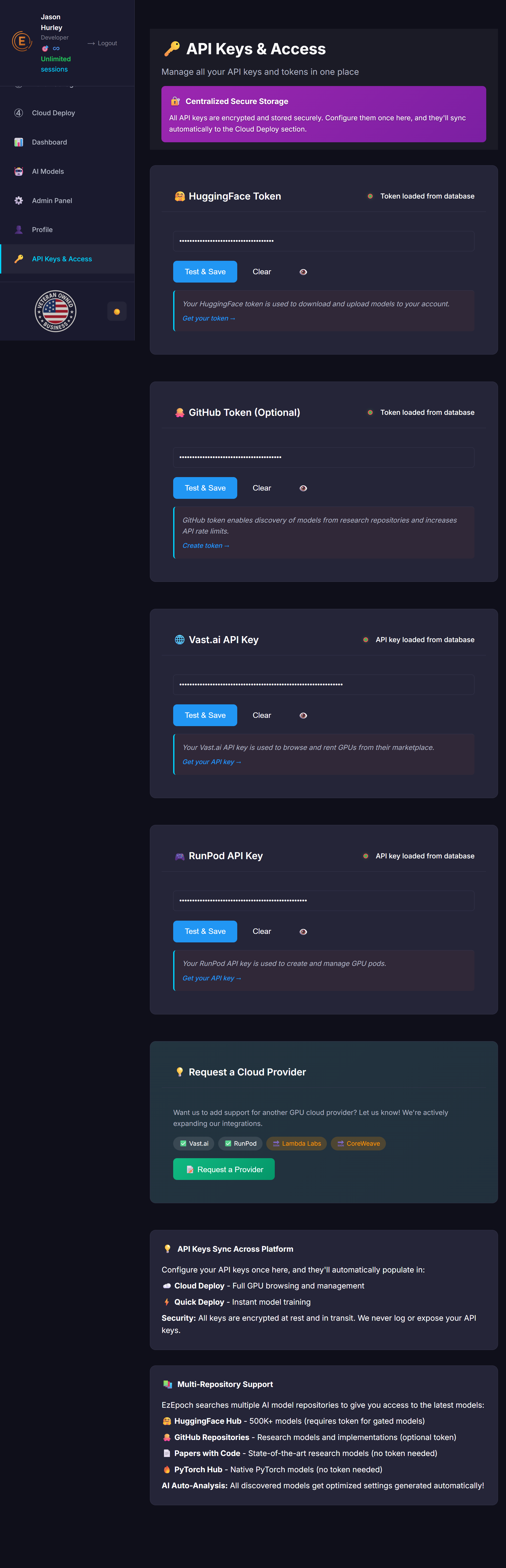
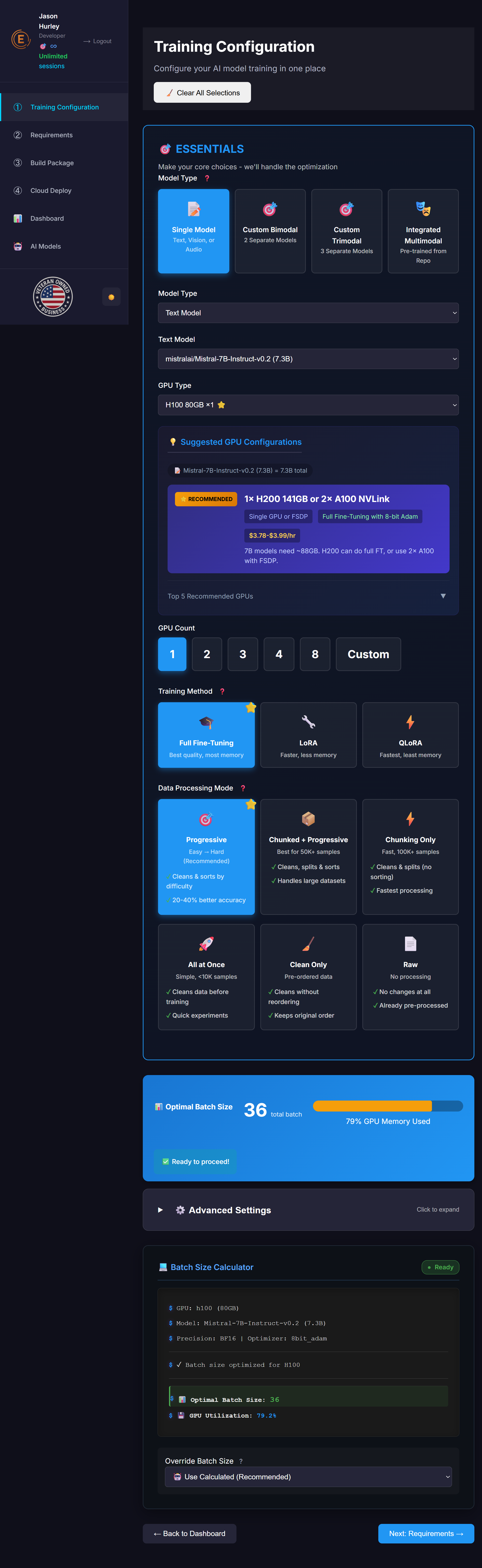
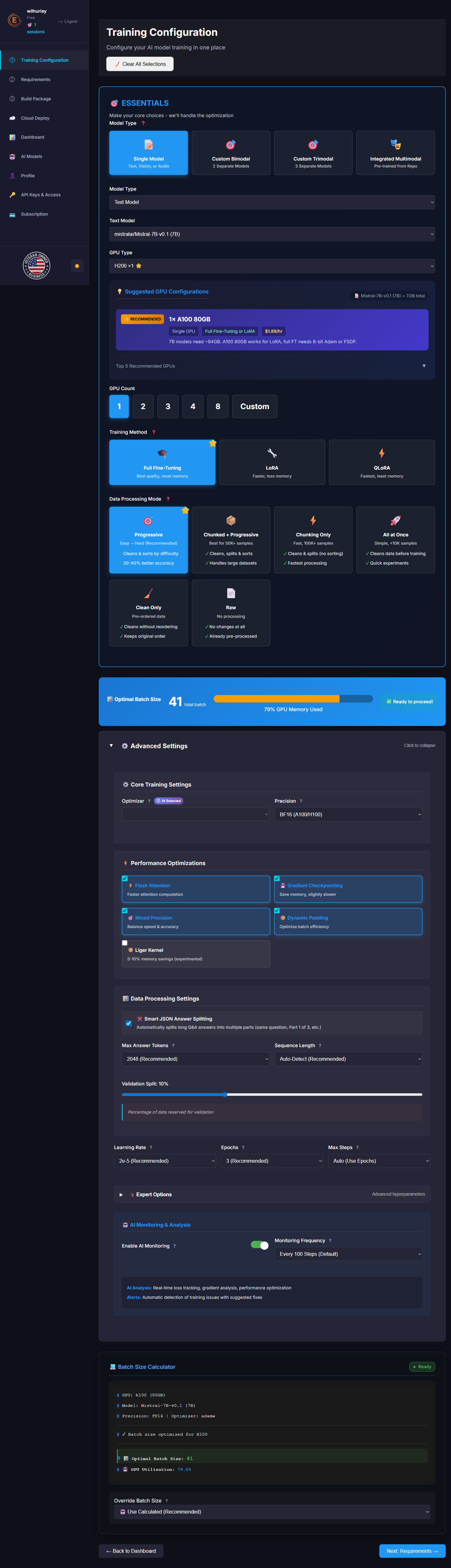
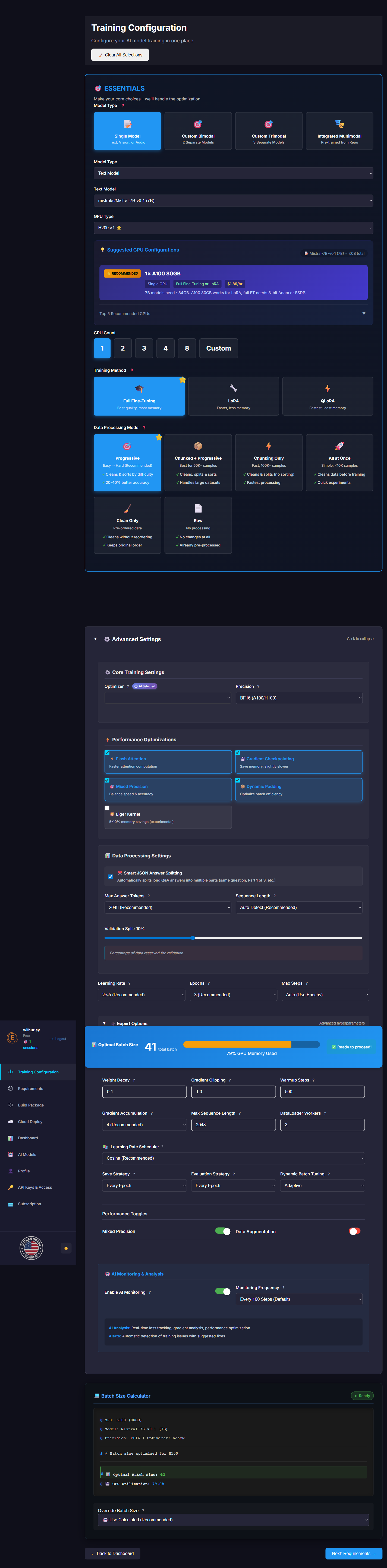
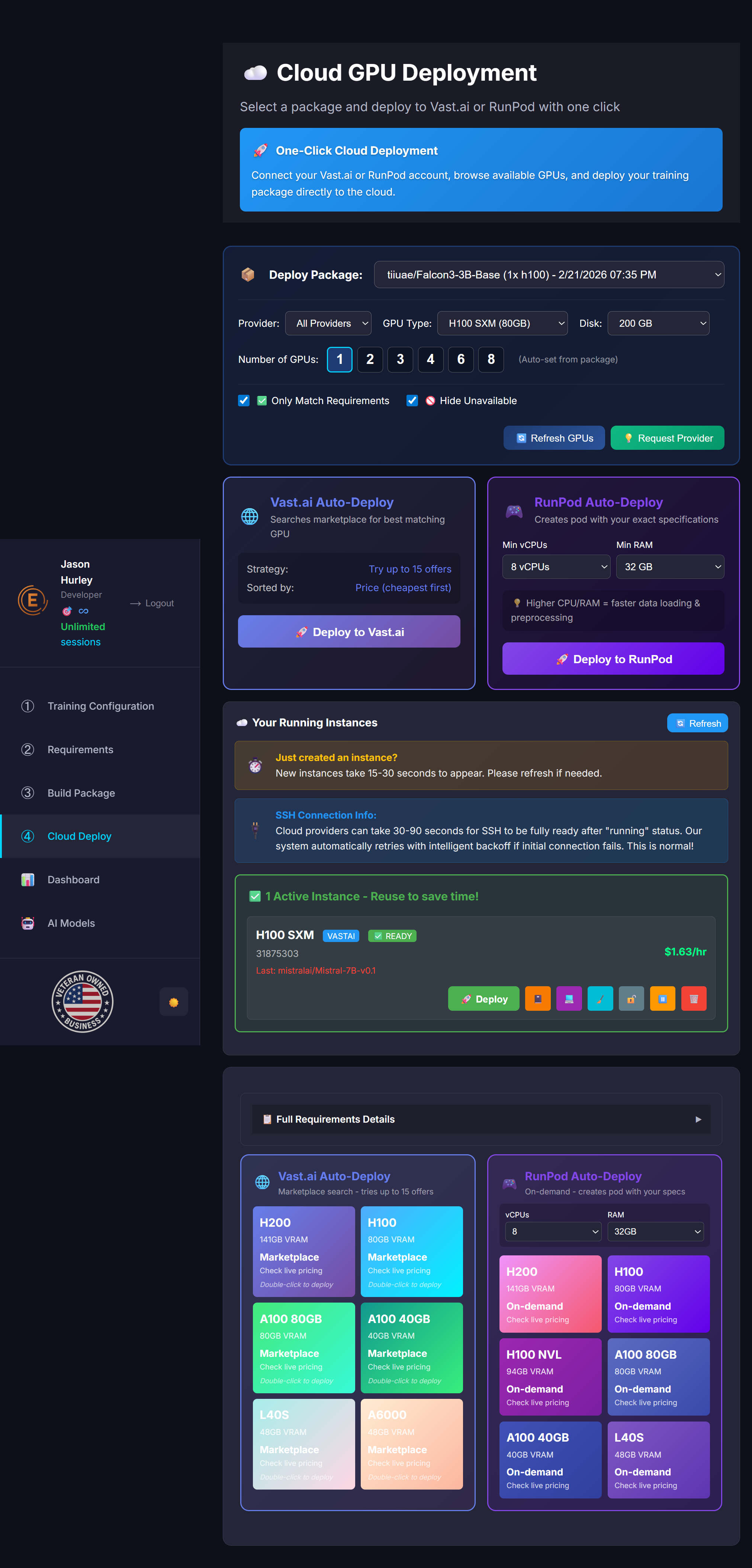
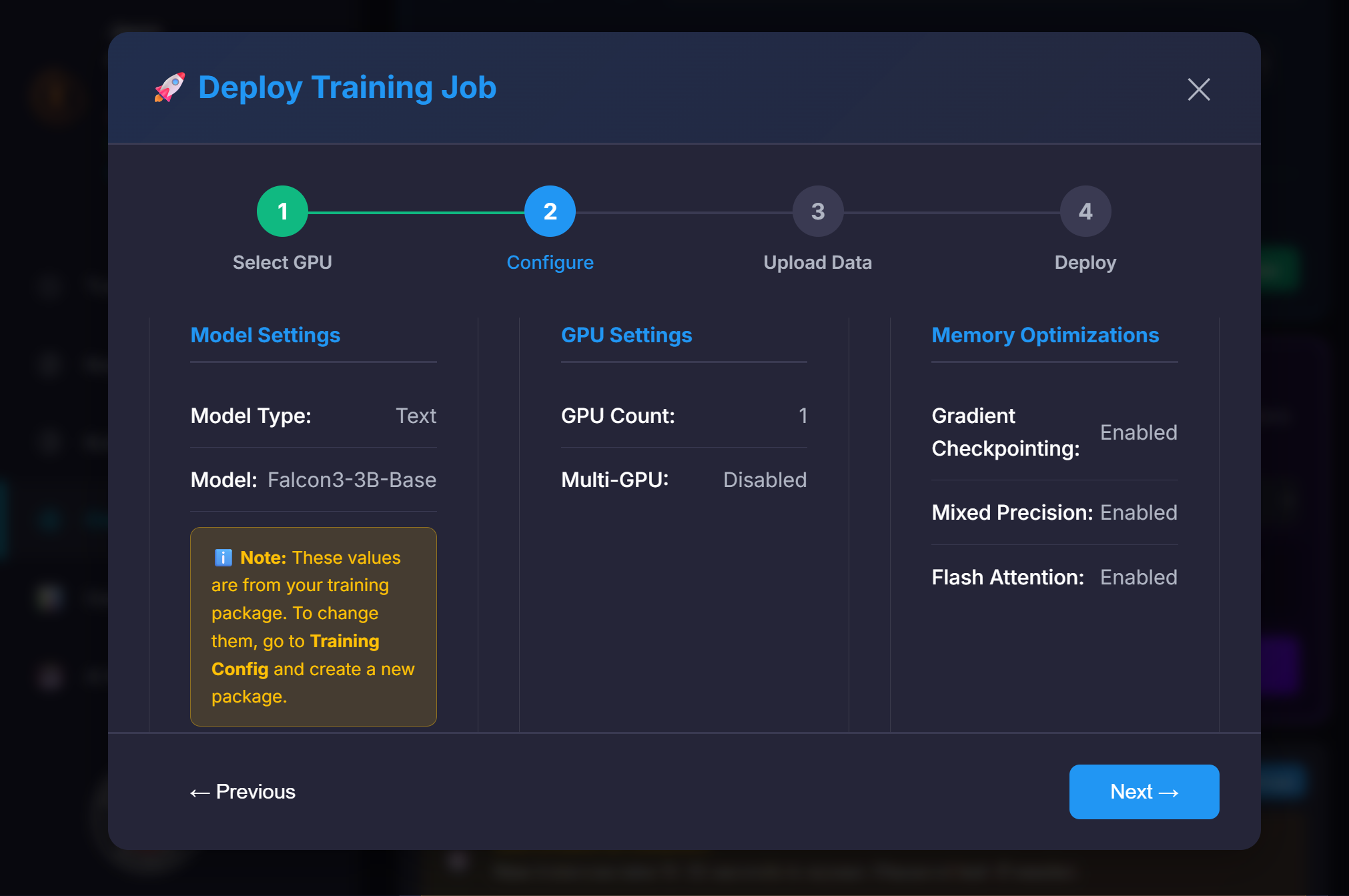
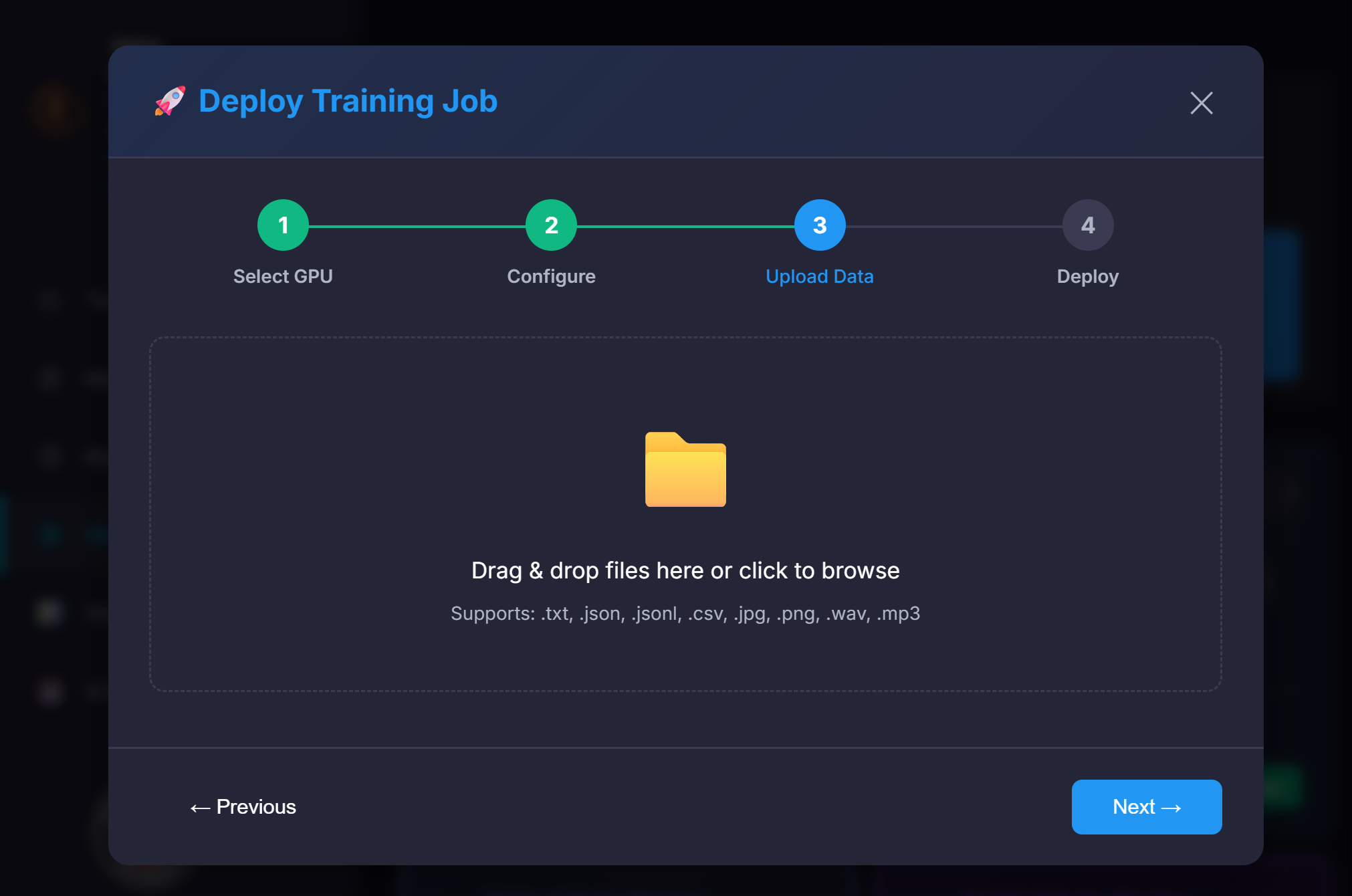
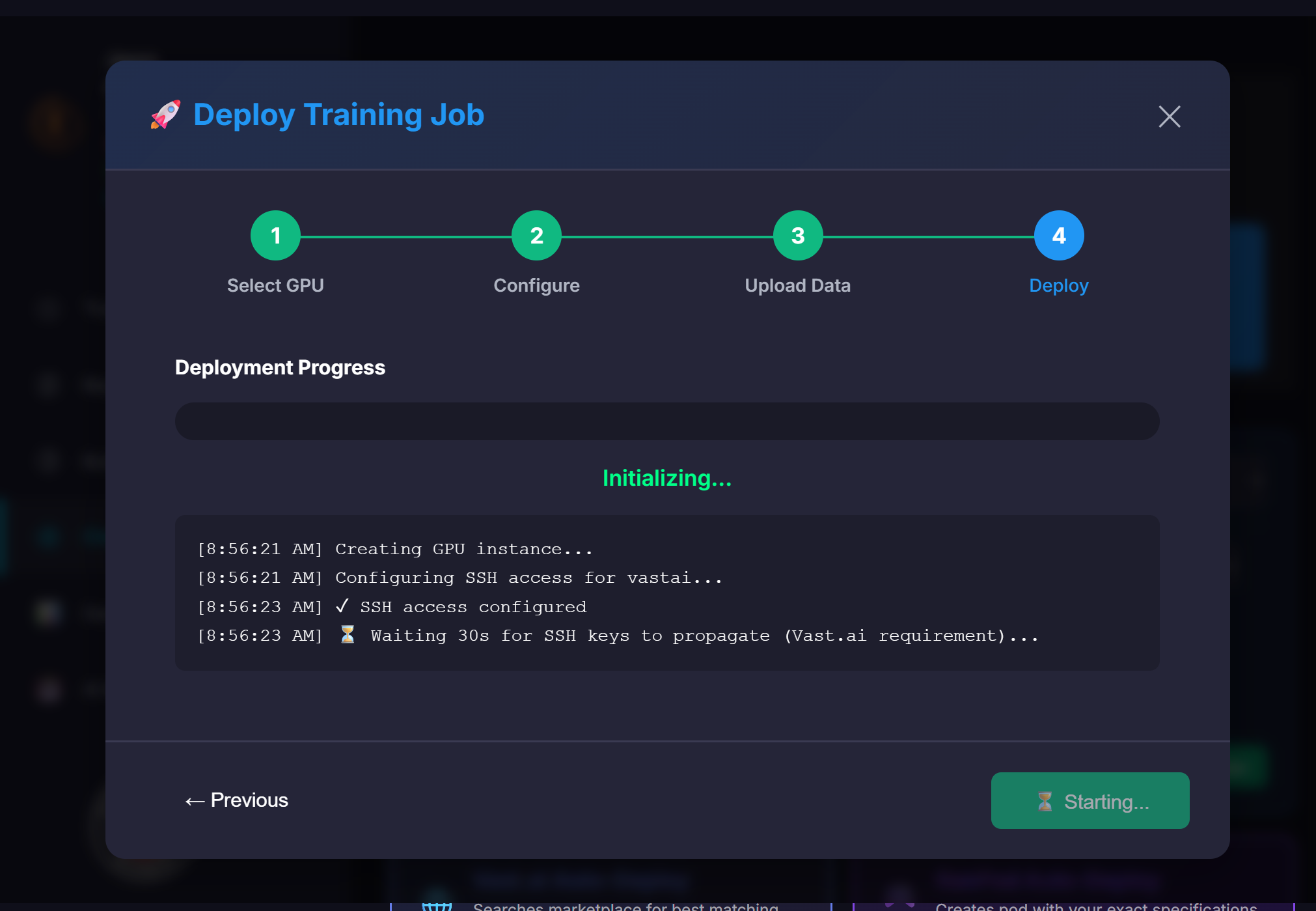
⚙️ Core Training Settings
⚡ Performance Optimizations
📊 Data Processing Settings
Percentage of data reserved for validation
🤖 AI Monitoring & Analysis
AI Analysis: Real-time loss tracking, gradient analysis, performance optimization
Alerts: Automatic detection of training issues with suggested fixes